Definition der Hochverfügbarkeit
Hochverfügbarkeit (engl. High Availability) umfasst ein Set an Technologien, Verfahren und Entwurfsprinzipien, die das Ziel der Business Continuity unterstützen. Für Systeme oder Services bedeutet das Ziel der Hochverfügbarkeit eine definierte, maximal tolerierte Ausfallzeit im Allgemeinen von 0,01%. Anders ausgedrückt: 99,99% Verfügbarkeit gelten z.B. lauf BSI als hochverfügbar.
Optimalerweise sind Systeme und Services zu 100% verfügbar, also während der vereinbarten Betriebszeit jederzeit zugreifbar. Dies ist jedoch selten realistisch und nur mit enorm hohem Aufwand abbildbar. Aus diesem Grund akzeptieren Unternehmen in vielen Bereichen definierte, maximale Ausfallszeiten, um die Kosten für Services in realistischen Bereichen zu halten.
Im betrieblichen Umfeld werden Verfügbarkeitsanforderungen häufig in Form von Service Level Agreements vereinbart. Dabei wird üblicherweise die Betriebszeit als Basis definiert (z.B. 7×24, also rund um die Uhr, oder Mo-Fr. Werktags von 08:00 bis 16:00 Uhr, also 5×8), wobei geplante Downtimes (z.B. Wartungsfenster) davon ausgenommen sind. Zusätzlich zur Betriebszeit ist der Mindestprozentanteil der Zeit definiert, den das System oder der Service mindestens zugreifbar sein soll (Uptime), z.B. eben diese 99,99% als Hochverfügbarkeit.
Mit solchen Vorgaben soll sichergestellt werden, dass alle für den Geschäftsbetrieb notwendigen Komponenten mit ausreichend großer Wahrscheinlichkeit zur Geschäftszeit genutzt werden können.
Verfügbarkeitsklassen
In der Praxis haben sich neben prozentualen Vorgaben bzw. Messungen vor allem die Verfügbarkeitsklassen der Harvard Research Group durchgesetzt, die Availability Environment Classification (AEC)
AEC-Klasse | Erklärung |
|---|---|
AEC-0 / Conventional | Service kann unterbrochen werden, Datenintegrität nicht essenziell z.B.: Systeme, die keine produktiven Daten speichern, unkritisch für den Geschäftsbetrieb sind. In vielen SAP-Umgebungen z.B. Sandbox-Systeme |
AEC-1 / Highly Reliable | Service kann unterbrochen werden, Datenintegrität muss jedoch gewährleistet sein Service kann unterbrochen werden, Datenintegrität muss jedoch gewährleistet sein z.B. Systeme, die nicht in produktiven Prozessen involviert sind, aber deren Funktion indirekt/mittelfristig Auswirkung auf diese haben kann. Im SAP-Umfeld häufig die regulären Entwicklungs- und QA-Systeme, da in diesen abhängige Datenstrukturen und Testfälle abgebildet sind, oder BW/BI-Systeme. |
AEC-2 / High Availability | Service darf während vereinbarter Zeiten oder zur Hauptbetriebszeit lediglich minimal unterbrochen werden z.B. Systeme, die während der Produktivzeiten eines Geschäftsprozesses kritisch sind. In SAP-Umgebungen sind dies häufig die Produktivsysteme |
AEC-3 / Fault Resilient | Service muss während vereinbarter Zeiten oder während der Hauptbetriebszeit ununterbrochen aufrechterhalten werden z.B. Systeme, deren Prozesse und Daten absolut kritisch für den Geschäftsprozess sind. In SAP-Umgebungen sind dies beispielsweise häufig die Systeme im Umfeld der Lagerverwaltung, vor allem für chaotische Lager, da ein Ausfall hier oft zu einer Vollinventur führen würde |
AEC-4 / Fault Tolerant | Service muss ununterbrochen aufrechterhalten werden, 24/7-Betrieb (24 Stunden, 7 Tage die Woche) muss gewährleistet sein
Wie oben, aber ohne Einschränkung der Betriebszeit. Dies umfasst häufig Systeme für Online-Services, bei denen Kunden schnell auf Alternativen umsteigen können, oder KRITIS-Umgebungen.
|
AEC-5 / Disaster Tolerant | Service muss unter allen Umständen verfügbar sein
Systeme, bei denen es dauerhaft um Leib und Leben geht, häufig im KRITIS-Umfeld z.B. in Kernkraftwerkumgebungen u.ä.. |
Tabelle 1: Verfügbarkeitsklassen nach AEC
Quelle: Harvard Research Group, https://hrgresearch.com/High%20Availability.html
Daneben gibt es weitere Klasseneinteilungen, wie die in Deutschland gängigen Verfügbarkeitsklassen des BSI:
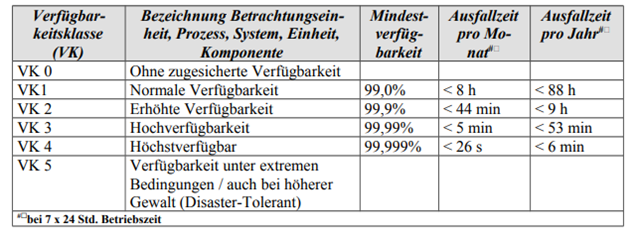
Abbildung 1: Verfügbarkeitsklassen nach BSI
Quelle: Bundesamt für Sicherheit in der Informaionstechnologie, HV-Kompendium, Band G, Kapitel 2: https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Hochverfuegbarkeit/BandG/G2_Definitionen.html
Berechnung der Hochverfügbarkeit
Verfügbarkeit wird üblicherweise in Prozent angegeben. Generell berechnet sich die Verfügbarkeit – und somit auch die Hochverfügbarkeit – indem die unterbrechungsfreie Leistungszeit eines Service durch die gesamte (vereinbarte) Betriebszeit geteilt wird.
Nicht zur Leistungszeit zählen dabei reguläre Wartungsfenster, die als geplante Downtimes in SLAs ebenfalls explizit geregelt werden.
100% Verfügbarkeit bedeutet ununterbrochener Betrieb während der vereinbarten Leistungszeit. Bei einem 7×24-Betrieb bedeuten die typischen “9er-Angaben” die folgenden maximalen Ausfallzeiten:
- 99 % ≡ 438 Minuten/Monat, also 7:18:18 Stunden/Monat = 87,7 Stunden/Jahr, d. h. 3 Tage und 15:39:36 h
- 99,9 % ≡ 43:48 Minuten/Monat, also 8:45:58 Stunden/Jahr
- 99,99 % ≡ 4:23 Minuten/Monat, also 52:36 Minuten/Jahr
- 99,999 % ≡ 26,3 Sekunden/Monat, also 5:16 Minuten/Jahr
- 99,9999 % ≡ 2,63 Sekunden/Monat, also 31,6 Sekunden/Jahr
99,9% Verfügbarkeit für ein einzelnes System herzustellen ist eine Herausforderung. Die gleiche Verfügbarkeit für einen Prozess mit z.B. drei Komponenten macht die Aufgabe jedoch ungleich größer: Verfügbarkeitsanforderungen multiplizieren sich.
So haben drei Komponenten mit jeweils 99,9% Verfügbarkeit eine Gesamtverfügbarkeit von lediglich 99,9% x 99,9% x 99,9% = 99,7%. Anstatt neun Stunden pro Jahr ist dies bereits deutlich über einen Tag. Hat eine der Komponenten eine Verfügbarkeit von nur 99%, erhöht sich die maximale Ausfallzeit bei 98,8% Verfügbarkeit sogar auf knapp viereinhalb Tage.
Somit muss bei komplexen Services die Einzelverfügbarkeit jeder kritischen Komponente beachtet und entsprechend hoch angesetzt werden.
Anwendungsbereiche der Hochverfügbarkeit
Je höher die vorgegebene Verfügbarkeit, desto mehr Aufwand und Kosten stecken in der aufzubauenden Infrastruktur. Das rechnet sich vor allem in solchen Branchen und Anwendungsfällen, in denen
- Ausfallzeiten hohe finanzielle Kosten nach sich ziehen (z.B. im Börsenhandel bzw. in der Finanzbranche allgemein, oder aber im Anwendungsfall chaotisch organisierter Großlager),
- Leib und Leben von der Verfügbarkeit der Infrastruktur abhängen (z.B. im Healthcare- oder auch im Flughafenumfeld) oder
- großflächige Folgen bei Ausfällen zu erwarten sind (typischerweise in den KRITIS-Umgebungen, oder bei Anbietern für große Infrastrukturumgebungen, z.B.im Cloudbereich, in Elektrizitätswerken).
Neben Umgebungen, in denen generelle Hochverfügbarkeit gefordert wird, gibt es auch Einsatzfelder, bei denen zeitpunktbezogen spezifische Anforderungen definiert sind. Dies gilt beispielweise für Berichtssysteme, die vielleicht nur quartalsweise ihren großen Auftritt haben, dann aber innerhalb eines bestimmten Zeitfensters verfügbar sein müssen. Andernfalls mit Strafen oder, noch schlimmer, schlechter Presse zu rechnen ist. Auch hier gilt es abzuwägen, wie welche Anforderungen konkret abgedeckt werden.
Hochverfügbarkeit SAP Hana
Besonderer Fall ist der Einsatz der HANA-Datenbanken im SAP-Umfeld. Bei Hochverfügbarkeitsanforderungen an S/4, BW/4 HANA o.ä. funktionieren viele klassische Methoden nur bedingt: Als In Memory-Datenbank schreibt die HANA-DB nicht alle Daten sofort auf physikalische Speichermedien, sondern hält sie lediglich im Arbeitsspeicher, ist also per se flüchtig. Deswegen bietet die HANA-Datenbanktechnologie eigene Mechanismen in Form einer synchronen Spiegelung mit der HANA System Replication an, ergänzt durch Cluster-Technologien der darunter liegenden Linux-Distributionen.
Kosten der Hochverfügbarkeit
Kosten der Hochverfügbarkeit steigen mit den Anforderungen. Die maximal tolerierten Ausfallzeiten, aber auch die Komplexität der Services spielen dabei eine zentrale Rolle.
Um Kosten zu reduzieren, bleiben nur wenige Möglichkeiten:
- Verfügbarkeitsanforderungen prüfen und ggf. Reduzieren – ggf. Auf Kosten der Servicequalität, wenn erlaubte Ausfallzeiten tatsächlich ausgenutzt werden (müssen)
- Geschäftsprozesse und Services vereinfachen, um die Anzahl der beteiligten kritischen Komponenten und somit der Verfügbarkeitsfaktoren zu reduzieren
- Kosteneffizientere Technologien einsetzen
- Kosteneffizientere Komponenten einsetzen
- Kosteneffizientere Verträge für externe Dienstleister abschließen
Umsetzung der Hochverfügbarkeit
Die technische Umsetzung einer Hochverfügbarkeitsumgebung hat in vielen Fällen etwas mit der Redundanz (also Doppelung) kritischer Systemkomponenten zu tun, um Single Points of Failure (SPOF) zu vermeiden, deren Ausfall zum Ausfall des Gesamtservices führen würde.
Hier sind im on-premises Betrieb – also bei eigenbetriebenen Umgebungen – vor allem zu nennen:
- Ausfallrechenzentren zur Doppelung der Systemstandorte bei großflächigen Vorkommnissen (Desastern)
- Clustertechnologien zur Doppelung von Servern bei Hardware-, Software- oder Netzwerkproblemen
- SAN- oder RAID-Technologien zur Doppelung von Storagekomponenten bei Hardwareproblemen
- USV (unterbrechungsfreie Stromversorgung) zur Doppelung der Stromversorgung
- Redundante Netzzugangspunkte zur Doppelung der Internetverbindung
Neben redundanten Komponenten gibt es auch noch die Klasse der ausfallsicheren Systeme, die in sich so strukturiert sind, dass sie 100%-Verfügbarkeit garantieren, aber dementsprechende Kosten mit sich bringen.
Bei Einsatz von Cloud-Strukturen bieten alle Hypervisor Technologien unterschiedlicher Verfügbarkeitsklassen an, mitsamt lokaler und/oder globaler Redundanzen.
Ebenso haben sich hybride Verfügbarkeitsszenarien im Markt etabliert, in denen Unternehmen beispielsweise on-premises- durch Cloud-Umgebungen absichern.
Zentrale Herausforderung für den technischen Aufbau hochverfügbarer Services ist jedoch deren Planung auf Basis der tatsächlichen Anforderungen. Hierfür gilt es die realen Prozesse und deren Anforderungen zu analysieren und daraus Vorgaben für die Einzelkomponenten einer Prozesskette abzuleiten. Dies hat sowohl technische wie auch wirtschaftliche Dimensionen – vor dem Hintergrund der Bepreisung eigener, marktkonformer Serviceangebote lautet das Motto üblicherweise “So viel wie nötig, so wenig wie möglich”.
In der Praxis existieren jedoch oftmals Service Level Agreements, die den tatsächlichen Anforderungen der High Availability nicht gerecht werden:
- unnötig hohe Vorgaben, was entsprechendes Kostenpotenzial in sich trägt,
- nicht ausreichende Verfügbarkeitsanforderungen für kritische Komponenten – was ein (zu) hohes Gesamtrisiko für den eigenen Service bedeutet.
- nicht definierte, “gefühlte” Service Level Anforderungen, die beliebig in beiden Dimensionen ausschlagen können.
Hier kommen oftmals externe Berater ins Spiel, die Prozesse sowohl technisch wie auch organisatorisch analysieren und mit Expertise beraten. Solche Anbieter und Dienstleister gewährleisten in der Regel eine objektive Unterstützung .Die Berater aus dem Hause Firnkorn und Stortz können Sie bei Einführung und Betrieb der Hochverfügbarkeit mit Fachwissen, Know-how und viel Praxiserfahrung unterstützen. Damit Sie Hochverfügbarkeit auch nur dort bezahlen, wo sie diese tatsächlich benötigen.
Lesen Sie außerdem mehr zu verwandten Themen
Ihr Ansprechpartner bei Firnkorn & Stortz zum Thema Hochverfügbarkeit
