Definition of high availability
High availability includes a set of technologies, procedures and design principles that support the goal of business continuity. For systems or services, the goal of high availability means a defined, maximum tolerated downtime of generally 0.01%. In other words: 99.99% availability is considered to be highly available.
Ideally, systems and services are 100% available, i.e. accessible at any time during the agreed operating hours. However, this is rarely realistic and can only be mapped with enormous effort. For this reason, companies in many areas accept defined, maximum downtimes to keep the costs for services within realistic ranges.
In the operational environment, availability requirements are often agreed in the form of service level agreements. The operating time is usually defined as a basis (e.g. 7×24, i.e. around the clock, or Monday to Friday on weekdays from 8 a.m. to 4 p.m., i.e. 5×8), with planned downtimes (e.g. maintenance windows) being included with exception of. In addition to the operating time, the minimum percentage of the time that the system or the service should be accessible (uptime) is defined, e.g. this 99.99% as high availability.
Such specifications are intended to ensure that all components required for business operations can be used with a sufficiently high degree of probability during business hours.
availability classes
In practice, in addition to percentage specifications and measurements, the availability classes of the Harvard Research Group, the Availability Environment Classification (AEC)
AEC class | Explanation |
|---|---|
AEC-0 / Conventional | Service can be interrupted, data integrity not essential
eg: systems that do not store productive data, are not critical to business operations. In many SAP environments, for example, sandbox systems |
AEC-1 / Highly Reliable | Service can be interrupted, but data integrity must be guaranteed Service can be interrupted, but data integrity must be guaranteed
e.g. systems that are not involved in productive processes but whose function can have an indirect/medium-term impact on them. In the SAP environment, it is often the regular development and QA systems, since dependent data structures and test cases are mapped in these, or BW/BI systems.
|
AEC-2 / High Availability | Service may only be interrupted minimally during agreed times or during main operating hours,
eg systems that are critical during the productive times of a business process. In SAP environments, these are often the productive systems |
AEC-3 / Fault Resilient | Service must be maintained uninterrupted during agreed times or during peak hours of operation,
eg systems whose processes and data are absolutely critical to the business process. In SAP environments, for example, these are often the systems in the warehouse management environment, especially for chaotic warehouses, since a failure here would often lead to a full inventory |
AEC-4 / Fault Tolerant | Service must be maintained uninterrupted, 24/7 operation (24 hours a day, 7 days a week) must be guaranteed As above, but with no restriction on uptime. This often includes systems for online services, where customers can quickly switch to alternatives, or KRITIS environments. |
AEC-5 / Disaster Tolerant | Service must be available under all circumstances Systems where life and limb are at stake, often in a critical environment, e.g.
in nuclear power plant environments, etc.
|
Table 1: Availability classes according to AEC
Source: Harvard Research Group, https://hrgresearch.com/High%20Availability.html
In addition, there are other classifications, such as the BSI availability classes commonly used in Germany:
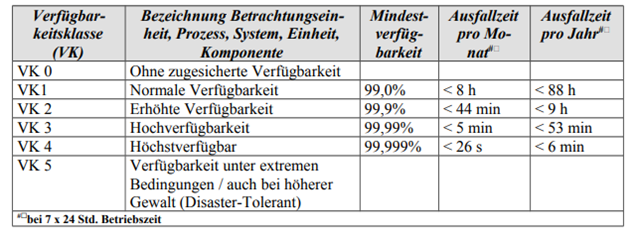
Figure 1: Availability classes according to BSI
Source: Bundesamt für Sicherheit in der Informaionstechnologie, HV-Kompendium, Band G, Kapitel 2: https://www.bsi.bund.de/SharedDocs/Downloads/DE/BSI/Hochverfuegbarkeit/BandG/G2_Definitionen.html
Calculation of high availability
Availability is usually given as a percentage. In general, the availability – and thus also the high availability – is calculated by dividing the uninterrupted service time of a service by the total (agreed) operating time.
Regular maintenance windows, which are also explicitly regulated as planned downtimes in SLAs, do not count towards the service time.
100% availability means uninterrupted operation during the agreed service period. With a 7×24 operation, the typical “9s” mean the following maximum downtimes:
- 99% ≡ 438 minutes/month, i.e. 7:18:18 hours/month = 87.7 hours/year, i.e. 3 days and 15:39:36 h
- 99.9% ≡ 43:48 minutes/month, i.e. 8:45:58 hours/year
- 99.99% ≡ 4:23 minutes/month, i.e. 52:36 minutes/year
- 99.999% ≡ 26.3 seconds/month, i.e. 5:16 minutes/year
- 99.9999% ≡ 2.63 seconds/month, i.e. 31.6 seconds/year
Areas of application for high availability
The higher the specified availability, the more effort and costs are involved in the infrastructure to be set up. This pays off above all in sectors and applications in which
- Downtimes entail high financial costs (e.g. in stock exchange trading or in the financial sector in general, or in the case of chaotically organized large warehouses),
- Life and limb depend on the availability of the infrastructure (e.g. in the healthcare or airport environment) or
- large-scale consequences are to be expected in the event of failures (typically in the KRITIS environments, or with providers for large infrastructure environments, e.g. in the cloud sector, in electricity plants).
SAP Hana high availability
A special case is the use of HANA databases in the SAP environment. In the case of high availability requirements for S/4, BW/4 HANA or similar, many classic methods only work to a limited extent: As an in-memory database, the HANA-DB does not write all data immediately to physical storage media, but only keeps it in memory, i.e. per se fleeting. For this reason, the HANA database technology offers its own mechanisms in the form of synchronous mirroring with the HANA system replication, supplemented by cluster technologies from the underlying Linux distributions.
costs of high availability
The costs of high availability increase with the requirements. The maximum tolerated downtimes, but also the complexity of the services, play a central role.
There are only a few options to reduce costs:
- Check availability requirements and reduce if necessary – possibly at the expense of service quality if permitted downtimes are actually (must) be used
- Simplify business processes and services to reduce the number of critical components involved and thus the availability factors
- Use more cost-effective technologies
- Use more cost-efficient components
- Conclude more cost-efficient contracts for external service providers
Implementation of high availability
In many cases, the technical implementation of a high-availability environment has something to do with the redundancy (i.e. duplication) of critical system components in order to avoid single points of failure (SPOF), the failure of which would lead to the failure of the entire service.
In on-premises operation – i.e. in self-operated environments – the following should be mentioned in particular:
- Backup data centers to double the system locations in the event of large-scale incidents (disasters)
- Cluster technologies to duplicate servers in case of hardware, software or network problems
- SAN or RAID technologies for duplicating storage components in the event of hardware problems
- UPS (uninterruptible power supply) to double the power supply
- Redundant network access points to double the Internet connection
- unnecessarily high specifications, which carries corresponding cost potential,
- insufficient availability requirements for critical components – which means a (too) high overall risk for your own service.
- undefined, “perceived” service level requirements that can swing arbitrarily in both dimensions.
Also, read more on related topics
Your contact at Firnkorn & Stortz on the subject of high availability

Firnkorn + Stortz GmbH
Thomas Firnkorn